The Monte Carlo method¶
Introduction¶
The Monte Carlo method is a very powerful tool of statistical physics. Monte Carlo methods are as useful as they are widespread. For example, one can also compute molecular dynamics using Monte Carlo methods. There's a reason it's named after Monaco's famous casino; it utilises probability and randomness. In most cases, a system is evolved to a new state which is chosen from a randomly generated ensemble of possible future states. Then, using some criteria, this new state is accepted or rejected with a certain probability. This can be used in many different areas of science, with end goals ranging from: reaching a Bose-Einstein ground state, minimizing an investment portfolio risk or optimizing the boarding process of an airplane. Considering the breadth of applications, we choose to center this second project on Monte Carlo methods.
While there are multiple categories of Monte Carlo Methods, we will focus on Monte Carlo integration. To see the advantage of this technique, consider a system that is described by a Hamiltonian depending on . This is the set of all system degrees of freedom. The Hamiltonian might include terms like a magnetic field , potential , etc. We're interested in a specific observable of this system called . Specifically, we'd like to know its expectation value . From statistical physics, all system state likelihoods can be summarized in the partition function: Where ) and the Hamiltonian is integrated over all system degrees of freedom. Here, the Boltzmann factor weighs the probability of each state. The expression for the expectation value can then be expressed as:
For most systems, is a collection of many parameters. For example, a system with atoms like in the molecular dynamics project would have degrees of freedom (positions and velocities). Hence, this is a high-dimensional integral. This means an analytic solution is often impossible. A numerical solution is therefore required to compute the expectation value. In the next section, we will demonstrate the purpose of sampling an integral and converting it into a sum, which is easier to solve for computers. Then, a bit later, you will see why Monte Carlo integration becomes beneficial quite quickly.
Monte Carlo integration¶
From integral to random sampling¶
To demonstrate the concepts of Monte Carlo integration, let's take a simple one-dimensional integral , and consider how to evaluate this integral numerically. Using the so-called rectangle or midpoint rule we can turn the integral into a sum: where . This is the simplest approximation for numerical integration, and of course there are higher-order approximations.
A different approach to evaluating the integral can be taken if we use concepts from the theory of random variables. To this end, consider a probability distribution of a random variable (then ). We can compute the expectation value of a function of this random variable as where are selected according to the probability distribution . In other words, here we are approximating the expectation value by taking a finite sample of the random variable .
Interestingly, we can use this approach also to evaluate the integral (1)! To this end, we write where we sample from the uniform probability distribution . This formula looks very much like Eq. (1), but now with the fundamental difference that the points are taken randomly over the interval , instead of using a regular grid. The error of this Monte Carlo integration then scales as as known from the central limit theorem.
When does this Monte Carlo integration become useful?
Monte Carlo integration and why it's beneficial for high-dimensional integrals¶
First, let's consider ordinary numerical integration. This includes rules also used in finite elements techniques, like Newton-Cotes. In the simplest case, one can divide an integration interval into sections of
While some numerical integration rules are better than others, one typically gets an error of:
Here, is the order of the integration method.
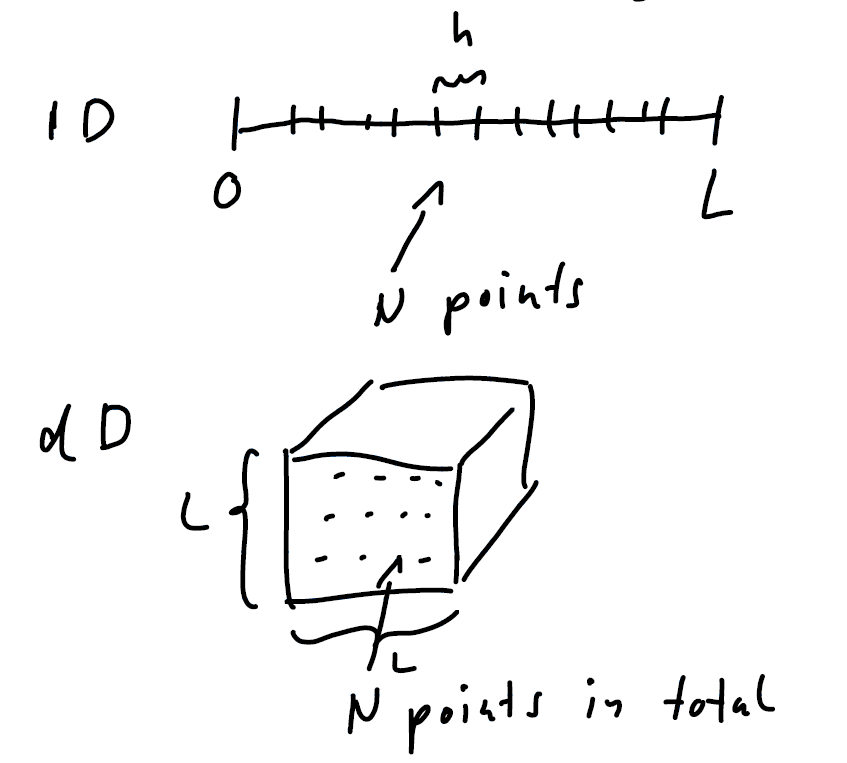 Now, we perform numerical integration in dimensions using the same N amount of d-dimensional sections. The error will behave like:
In the previous section, we have established that Monte Carlo integration has an error . This means that Monte Carlo has smaller errors when . For integrating a Hamiltonian with many degrees of freedom, this condition is met very quickly.
Now, we perform numerical integration in dimensions using the same N amount of d-dimensional sections. The error will behave like:
In the previous section, we have established that Monte Carlo integration has an error . This means that Monte Carlo has smaller errors when . For integrating a Hamiltonian with many degrees of freedom, this condition is met very quickly.
Now that I have your attention, let's go to the really interesting part.
The need for importance sampling¶
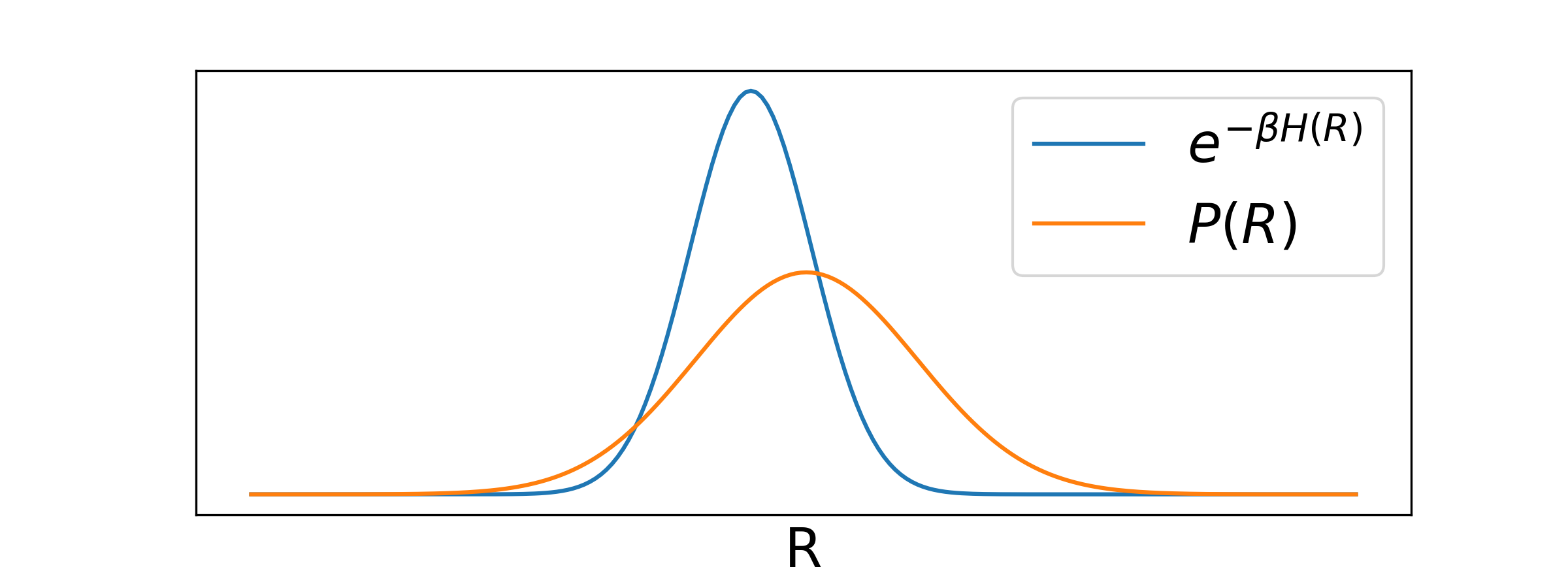
We could thus use Monte Carlo integration to evaluate sampling uniformly over the configuration space described by . However, this wouldn't be very efficient typically: In this integral we have the Boltzmann factor that is non-zero only in a small region of configuration space (only a small region is physically relevant), as shown schematically in the sketch below:

Sampling uniformly will in most cases sample an irrelevant configuration. Note that also in this case we would be guaranteed that the error of integrations drops like in the limit of - but we will never practically reach it.
From Eq. (2) we see that we do not need to sample uniformly. Instead, we should be sampling from a random probability distribution that is concentrated in the physically relevant space. This is called importance sampling. In the following we will discuss two different approaches to importance sampling.
Approximate importance sampling¶
Sampling almost the right probability distribution¶
Let us consider the general case of computing the expectation value of a function for a random variable distributed according to .
(In the previous example, . We consider the general case here.)
We then have to calculate the integral
Ideally, we would now generate random variables that are distributed according to . However, this may be impractical. In this
case we could instead try to sample from a nearby distribution :
 In this way we can make sure to approximately focus on the physically relevant configurations.
In this way we can make sure to approximately focus on the physically relevant configurations.
Doing this requires us to rewrite the integral as where the configurations are now sampled from . When using this approximate probability distribution we thus have to introduce weights into the average.
Why approximate importance sampling eventually fails¶
Approximate importance sampling is an attractive way of sampling: if we have a convenient and computationally efficient we can apply the Monte Carlo integration and seemingly focus on the relevant part of the configuration space.
Unfortunately, this approach becomes increasingly worse as the dimension of the configuration space increases. This is related to the very counter-intuitive fact that in high-dimensional space "all the volume is near the surface". This defies our intuition that is trained on dimensions .
Let us look at a simple example. Consider two hypercubes in dimensions. The two hypercubes have side lengths , so their volume is . We now consider that the two hypercubes are shifted slightly with respect to each other, such that their overlap in every Cartesian coordinate direction is with , as schematically sketched in 2D below:

We can now compute the ratio of the overlap volume to the volume of the hypercubes and find So even for a slight shift, the overlap ratio will decrease exponentially with dimension.
This is also a problem when we sample with only a nearby probability distribution function. As the dimensionality of the configuration space increases, the overlap between the actual and the nearby probability distributions vanishes, and we keep on mostly sampling uninteresting space.
This effect directly shows up in the weights. Let us demonstrate this using a simple example. Consider the case
where
is a normal distribution with standard deviation . For the sampling distribution we use
also a normal distribution, but with a slightly different standard deviation :
We will now compute how the weights are distributed for different dimensionality
. In the example below we have chosen and and sampling over
configurations:
 We see that as dimensionality increases, the distribution of weights gets more and more skewed towards 0. For a large dimensionality,
almost all weights are very close 0! This means that most configurations will give little contribution to the weighted average
in Eq. (3). In fact, this weighted average will be determined by the very few configurations that were close to ,
and we end up with few physically relevant configurations again.
We see that as dimensionality increases, the distribution of weights gets more and more skewed towards 0. For a large dimensionality,
almost all weights are very close 0! This means that most configurations will give little contribution to the weighted average
in Eq. (3). In fact, this weighted average will be determined by the very few configurations that were close to ,
and we end up with few physically relevant configurations again.
So in high-dimensional configuration space approximate importance sampling will eventually break down. The only way out is to sample even closer to . The ideal case would be to sample exactly from !
Metropolis Monte Carlo¶
Markov chain Monte Carlo¶
This leaves us a practical question: Can we sample exactly from an arbitrary ? The answer is, maybe surprisingly, yes, and lies in using Markov chains.
So what is a Markov chain? Consider a sequence of random states . We say that the probability of choosing a new random state only depends on , not any other previous states. Now, one can transition from one state to the other with a certain probability, which we denote as: . This rate is normalised: . This simply means: you have to go to some state.
We can then write a rate equation to see what the chance is of obtaining state at step :
But we want this Markov chain to eventually sample our probability distribution . This means that we want the probability to be stationary, such that we always sample the same distribution: This simplifies the rate equation to: There are different ways for solving this equation. It is for sure solved by This particular solution of the rate equation is called detailed balance.
We can thus generate a desired probability distribution by choosing the right . This leads to the question: how do we generate the terms to get the correct probability distribution? The Metropolis algorithm solves this problem!
The Metropolis algorithm uses the following ansatz: . Here, the generation of the new state in the Markov chain is split into two phases. First, starting from the previous state , we generate a candidate state with probability . This is the so-called "trial move". We then accept this trial move with probability , i.e. set . If we don't accept it, we take the old state again, . Altogether, the probability of going to a state new state () is the product of proposing it () and accepting it (.
The problem can be further simplified by demanding that - the trial move should have a symmetric probability of going from to and vice versa. The detailed balance equation then reduces to: Metropolis et al. solved this as: The key to understanding why Eq. (5) solves (4) is to observe that and will necessarily be given by different cases in Eq. (5).
Summary of Metropolis algorithm¶
- Start with a state
- Generate a state from (such that )
- If , set
If , set with probability
else set . - Continue with 2.
What determines the quality of the Metropolis sampling?¶
With the Metropolis algorithm we have a general procedure to sample according to any arbitrary probability distribution . In fact, the procedure works for any kind of arbitrary trial move (as long as the probabilities are symmetric) - we never detailed the move. It seems that Metropolis is pure magic!
What we need to realize is that we pay for the generality of the Metropolis algorithm with correlation. In fact, the degree of correlation is determined by the trial moves. A useful measure to determine the usefulness of a trial move is the acceptance ratio .
Let us demonstrate this using a simple example, and use the Metropolis algorithm to generate a Markov chain that
samples a normal distribution . In this case, our configuration space
is simply the real axis. As a trial move, we can randomly move a distance away from the original point:
This trial move has symmetric probability for every distance . Still, the choice of determines very strongly the
correlation of the Markov chain as demonstrated below (for these simulation we used and 200 Markov steps):
 In these pictures the probability distribution is indicated by the shades of grey. The values in the Markov chain are plotted in blue.
In these pictures the probability distribution is indicated by the shades of grey. The values in the Markov chain are plotted in blue.
When choosing a too large value of (left picture) we easily "overshoot" and land in a region with low probability. Hence, the resulting acceptance ratio is small. But this leads to the Markov chain containing many repeated values as we keep on using the old value if the move is rejected! This leads to strong correlation and we sample effectively little independent data points.
When the value of is chosen too small (right picture) every move changes little about the configuration. As a consequence, the acceptance ratio is very large, but the speed with which we sample the configuration space is very slow. In fact, as seen above in this case only a part of the probability distribution is really sampled.
It is thus important to design the trial move in order to reduce correlation. In the example, this happens at some intermediate value of . In many cases, such as here, the rule of thumb is that an acceptance ratio is a good target. But this depends on many aspects of the system.
In the end, the success of the Metropolis algorithm critically hinges on designing a good trial move.
Calculating the error of a mean computed using the Metropolis algorithm¶
The Metropolis algorithm generates correlated data . As in the molecular dynamics project, we can use this data to estimate the mean, but when calculating the error of the mean it is essential to account for the correlations.
Which method is better?¶
The Metropolis algorithm has developed into one of the most important tools for importance sampling. Yet, it is not per se the superior method. As we saw, success of the Metropolis algorithm depends on designing a good trial step. This may not be easy for all situations. In addition, Metropolis necessarily generates correlated random numbers - compared to approximate importance sampling that can generate independent random configurations. Hence, the choice of method really depends on the problem at hand, and is in the end more a practical question of how well a method can be applied to a specific case.
This is also reflected in the three different project choices you have for the second project. Two of them use the Metropolis algorithm (the simulation of the Ising model and the variational quantum Monte Carlo simulation), whereas the third uses approximate importance sampling (simulating polymers).